

본 글은 ComfyUI를 설치하고 Wan2.1모델을 이용해서 Image to Video에 대한 설명글입니다. 참고로, Wan2.1모델은 Image to Video, Text to Video 등을 지원하고 있습니다. 여러가지 활용 방안이 있으나 이 글에서는 가장 활발히 사용되는 Image to Video에 대해서만 집중적으로 다루도록 하겠습니다.
1.Wan 2.1
Wan 2.1 은 중국 알리바바에서 개발하여 2025년 2월에 공개한 오픈소스 비디오 생성 모델입니다.
중국 텐센트 등 여러 단체 및 기업들에서 비디오 생성 모델들을 내놓았는데, Wan 2.1은 현존 모델들을 벤치마크 상 가장 앞선다고 알려져 있습니다.
비디오 생성 모델들이 고성능 비디오 카드를 요구하던 것과 달리, Wan2.1 모델로 가정용 그래픽카드를 이용하여 480p, 720p, 심지어 1080p 영상을 생성할 수 있습니다.
Wan2.1 모델은 Text-to-Video, Image-to-Video, 그리고 Video-to-Video로 영상 생성이 가능합니다.
2. ComfyUI
ComfyUI는 Stable diffusion과 같은 확산형 생성 모델을 보다 편리하게 사용할 수 있도록 도와주는 GUI 도구입니다. ComfyUI에는 여러가지 박스(노드)를 연결하여 워크플로우를 구성하고, 생성 모델을 실행할 수 있도록 도와줍니다.
Stable dIffussion용 웹 GUI로 AUTOMATIC1111를 가장 많이 사용하고 있는데, 이 AUTOMATIC1111에 비해 ComfyUI는 직관적이고 쉬우며 경량이어서 빠르다는 장점이 있습니다. 이미지 생성뿐만 아니라 여러 비디오 생성 모델을 쉽게 노드로 적용할 수 있고, Wan2.1과 같은 새로운 모델이 나오면 빠르게 Custom Node가 오픈소스로 공개되어 사용자들이 손쉽게 새로운 모델을 사용할 수 있도록 해줍니다.
2.1. ComfyUI 설치하기
※ 이 설치 및 사용법은 NVIDIA 그래픽 카드가 장착된 윈도우 PC 및 노트북을 기준으로 설명합니다.
ComfyUI 설치는 비교적 쉽습니다. 포터블 설치가 가능하므로, git 정도만 설치하면 됩니다.
git 설치는 [이곳]에서 확인할 수 있습니다.
ComfyUI는 아래 주소에서 다운로드 받을 수 있습니다.
https://github.com/comfyanonymous/ComfyUI/releases
2025년 3월 27일 기준 최신 버전은 0.3.27입니다.
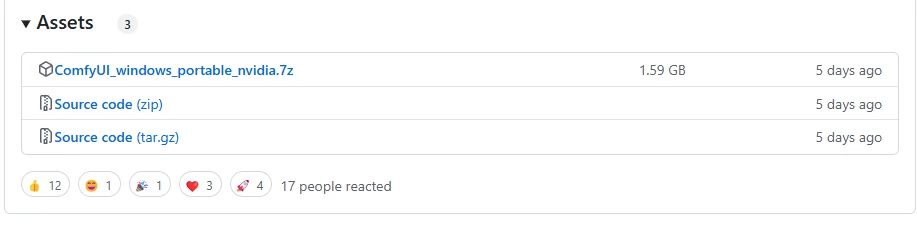
포터블 버전은 ComfyUI_windows_portable_nvidia.7z 파일을 다운로드 받습니다.
다운로드 받은 포터블 버전을 원하는 위치에 압축해제 합니다. 압축해제 하면 아래와 같은 파일과 폴더를 확인할 수 있습니다.
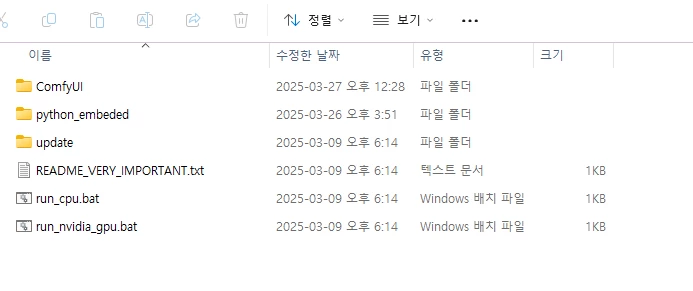
각종 커스텀 노드를 설치할 차례가 남아있는데, 추후 run_nvidia_gpu.bat를 통해 실행할 것입니다.
2.2. 커스텀노드 설치
2.2.1. Video Help Suite 노드 설치
https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
각종 비디오와 관련된 작업을 도와주는 노드들입니다. Video Helper Suite의 Video Combine 노드를 이용해 여러 이미지를 합쳐 mp4 파일로 생성하는 작업을 할 것입니다.
윈도우 명령프롬프트를 열고 압축 해제한 폴더 (ComfyUI_windows_portable)로 이동합니다.
ComfyUI_windows_portable 폴더에서 ComfyUI > custom_nodes 로 이동합니다.
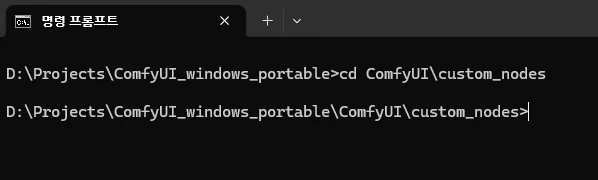
해당 폴더에서 다음 명령어를 입력합니다.
git clone https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
해당 노드에 대한 필요 패키지들을 설치합니다. 포터블 버전으로 설치했기 때문에 내장된 python (python_embeded 폴더에 위치)을 이용합니다.
먼저 다시 ComfyUI_windows_portable폴더로 이동합니다. 그리고 아래 명령어를 실행합니다.

python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-VideoHelperSuite\requirements.txt
2.2.2. UI Manager 설치 (옵션)
UI Manager는 ComfyUI의 각종 패키지들을 편리하게 관리할 수 있도록 해주는 도구입니다.
윈도우 명령프롬트프에서 ComfyUI_windows_portable 폴더에서 ComfyUI > custom_nodes 로 이동합니다.
다음, 아래 명령어를 입력합니다.
git clone https://github.com/ltdrdata/ComfyUI-Manager
다시 ComfyUI_windows_portable폴더로 이동합니다. 그리고 아래 명령어를 실행합니다.
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-Manager\requirements.txt
2.3. 모델 파일 다운로드 및 복사
이제 Wan2.1의 모델 파일을 다운로드 받습니다.
2.3.1. 디퓨전 모델 파일
Diffusion model 파일은 아래 주소에서 다운로드 받을 수 있습니다.
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models
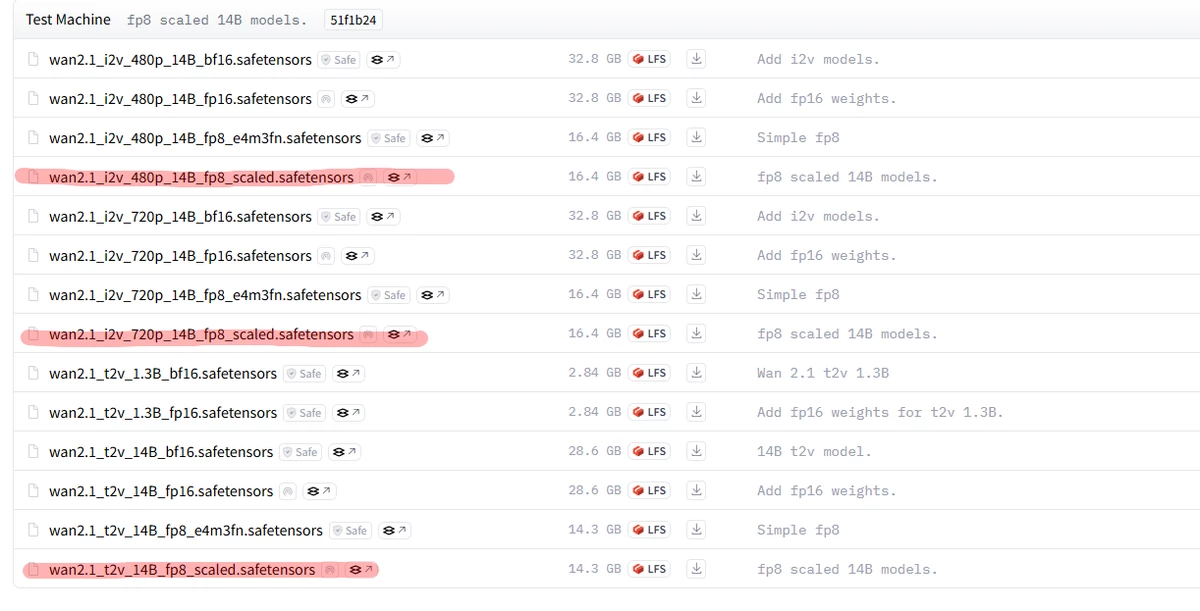
이미지 to 비디오 모델은
wan2.1_i2v_480p_14B_fp8_scaled.safetensors (480p 영상, 일반 고성능 GPU / VRAM 12GB이하 추천)
wan2.1_i2v_720p_14B_fp8_scaled.safetensors (720p 영상, 하이엔드 고성능 GPU / VRAM 12GB이상 추천)
다운받은 모델은
ComfyUI_windows_portable > ComfyUI > models > diffusion_models
폴더에 넣어줍니다.
2.3.2. CLIP VISION 파일
아래 주소로 접속해서 clip_vision_h.safetensors 파일을 다운로드 받습니다.
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/clip_vision
다운받은 파일은
ComfyUI_windows_portable > ComfyUI > models > clip_vision
폴더에 넣어줍니다.
2.3.3. TEXT ENCODER 파일
아래 주소로 접속하여 umt5_xxl_fp16.safetensors 파일을 다운로드 받습니다.
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
다운받은 파일은
ComfyUI_windows_portable > ComfyUI > models > text_encoders
폴더에 넣어줍니다.
2.3.4. VAE 파일
아래 주소로 접속하여 wan_2.1_vae.safetensors 파일을 다운로드 받습니다.
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
다운받은 파일은
ComfyUI_windows_portable > ComfyUI > models > vae
폴더에 넣어줍니다.
3. 실행 및 설정 (Image to Video)
명령프롬프트에서 ComfyUI_windows_portable 폴더로 이동하여 run_nvidia_gpu.bat를 실행합니다.

잠시 후, 웹브라우저로 ComfyUI가 나타납니다.
워크플로우 파일 다운로드:
아래와 같이 [WAN2.1_i2v_480p.json]에 접근해서 워크플로우 파일을 다운로드 받습니다.
(해당 파일은 ConfyUI 공식 예제 파일을 기반으로 업스케일 및 프레임 보간을 거치며 최종 영상 파일로 최종 인코딩 되도록 수정한 버전입니다. 필요 노드는 별도 추가하시기 바랍니다.)

다운받은 워크플로우 json 파일을 ComfyUI 웹브라우저 화면으로 드래그 앤 드롭해주면 워크플로우가 나타납니다.
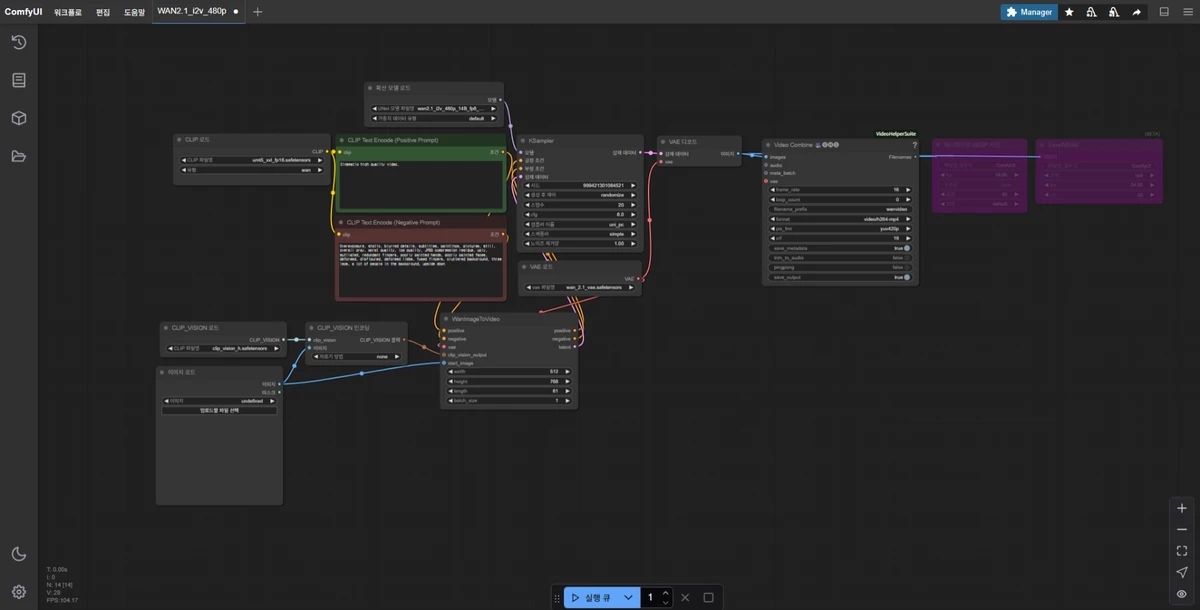
주요 노드들을 하나씩 살펴보면 다음과 같습니다.
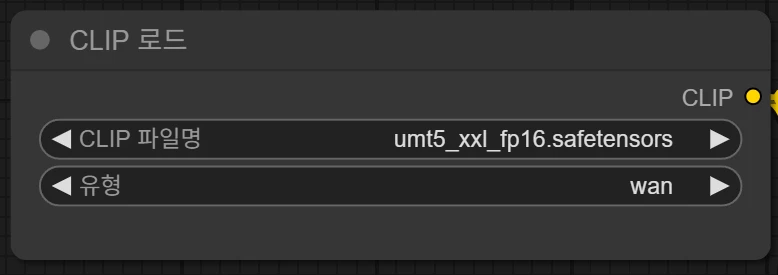
이 부분은 CLIP 파일명 부분을 클릭하여 실제 다운로드 받은 text encoder 파일을 선택해 줍니다.
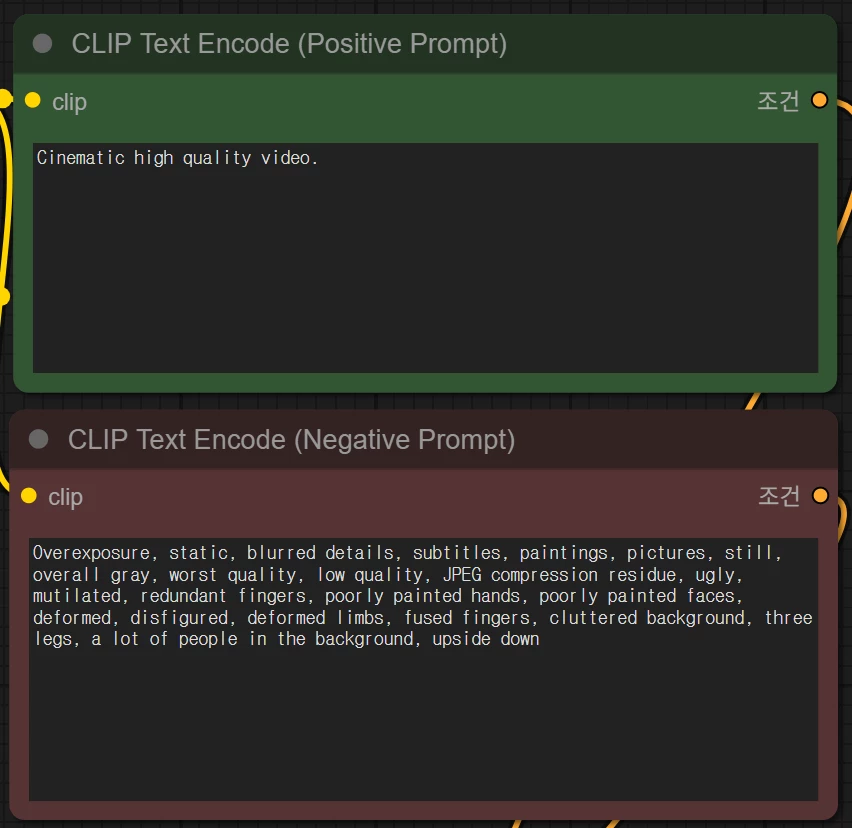
프롬프트 영역입니다. Stable Diffusion과 같이 긍정/부정 프롬프트를 작성합니다. Wan 모델은 영어와 중국어를 인식할 수 있습니다.
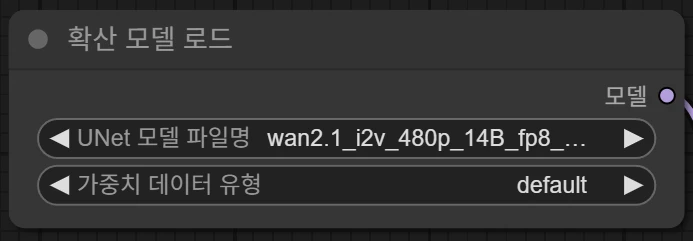
디퓨전 모델을 선택하는 영역입니다. 파일명을 클릭하여 실제 다운로드 받은 모델 파일을 선택해줍니다.
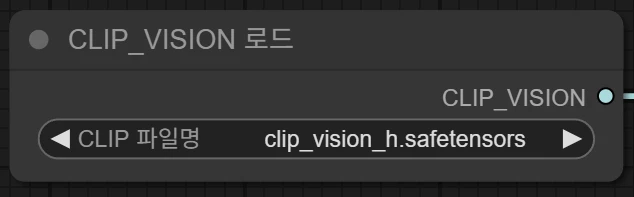
CLIP VISION노드에서도 실제 다운받은 파일로 지정해 줍니다.
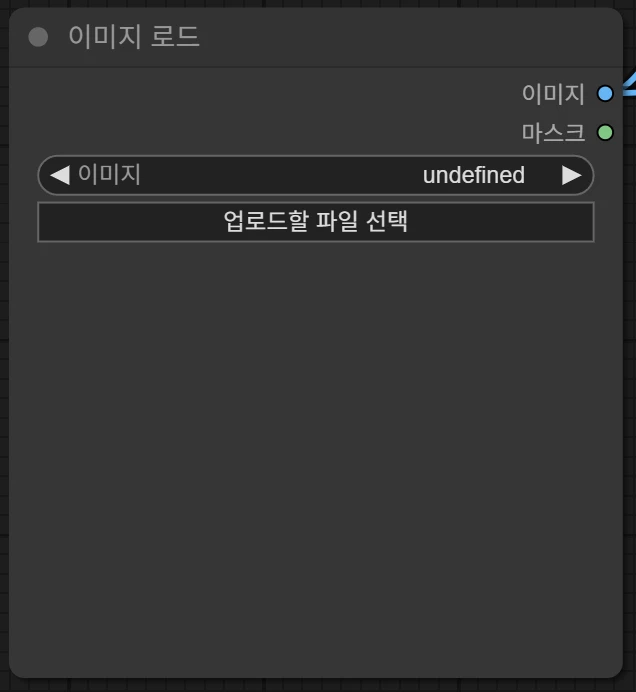
이 노드는 Image to Video에서 Image를 지정하는 부분입니다. 업로드할 파일을 선택하거나 이 영역으로 이미지를 드래그 앤 드롭하면 됩니다.
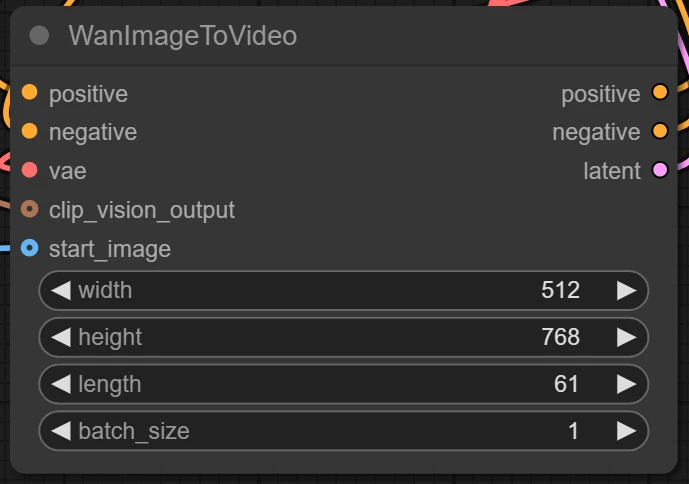
비디오 크기를 지정하는 영역입니다. 480p 기준으로 480 * 720 사이즈로 지정하는게 일반적입니다.
length는 비디오의 길이를 결정합니다. 영상 초당 프레임을 기준으로 영상의 전체 시간이 결정됩니다.
VRAM이 부족하면 length를 줄여보시기 바랍니다. 단, 이러면 영상이 매우 짧아질 수 있습니다.
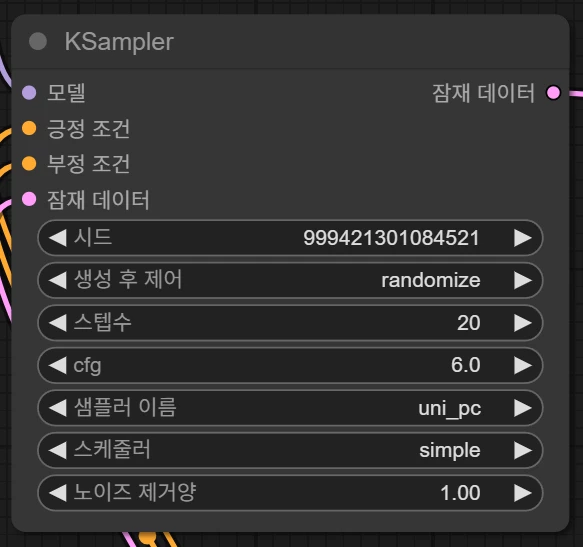
중요한 노드 중 하나인 샘플러 설정 노드입니다.
스텝수가 증가하면 연산 시간도 늘어나지만 영상의 퀄리티도 좋아지는 것으로 확인되었습니다.
15~30 사이로 지정하는 것이 일반적이며, 20정도를 추천합니다.
cfg는 프롬프트의 반영 정도 혹은 창의성 부분을 관여합니다. 수치가 높을수록 프롬프트에 충실해 지지만 너무 높은 수치는 잘못된 결과를 초래할 수 있습니다.
샘플러 등도 여러가지로 테스트해보실 수 있습니다.
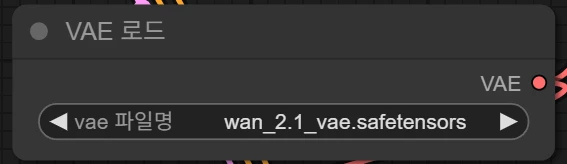
이 노드에서도 아까 전에 다운받은 VAE파일을 지정해 줍니다.
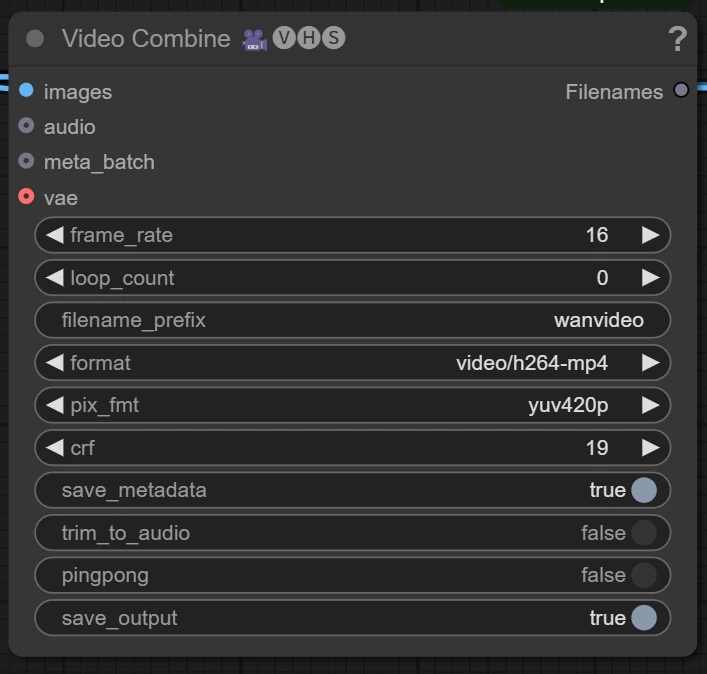
최종 영상 파일을 설정하는 노드입니다.
frame_rate는 말 그대로 초당 프레임 수입니다. 그래도 두시는 것을 추천합니다.
crf는 압축률입니다. 건드리지 않는 것을 추천합니다.
또한 이 노드에서 mp4 말고도 gif등으로 지정할 수 있으니 원하는 파일 포맷으로 지정할 수 있습니다.

모든 설정이 완료되면 실행 버튼을 누르시면 생성이 시작됩니다.
GPU성능에 따라 수분 ~ 수십분 또는 몇시간이 걸릴 수 있습니다.
메모리 부족 오류가 발생하면 설정을 조정해 보시기 바랍니다.
아래는 공식 샘플 이미지를 이용해서 직접 생성해 본 영상입니다.
이상으로 Wan2.1 기반 Image to Video 가이드를 마치겠습니다.
기본적인 사항만 다룬 글이라 다소 부족할 수 있습니다. 추가 문의사항이나 의견이 있으시면 댓글로 자유롭게 남겨주세요.
감사합니다.
⚠️ 무단 펌을 금합니다. ⚠️
첨부파일 21
-
84f8fc12792a484f2ea23caae99fc349.webp
20.9KB
-
45cfc72d06fe96297bd06290a9dcf5a4.webp
12.2KB
-
49d74101db0f8061ba352a23e7c6753c.webp
18.9KB
-
cdc71ccaf709df0f4dfa94da0e681d6b.webp
9.2KB
-
085e751bc5c0481d43610ae6f83241ad.webp
2.7KB
-
b9d6d3de04c4d64b6c6dd5c932b60a1b.webp
73.9KB
-
040097456a21c94be2f0d2ae5349b4d3.webp
3.8KB
-
f937ba55387e4e0001186966ae811752.webp
26.6KB
-
20628a981bf603164597647c8e9b2bbf.webp
7.7KB
-
19dadad320ae77180f53d6ca87c4791e.webp
30.1KB
-
c057116460f828b7a604faefcec5c613.webp
8.6KB
-
94ae04c58497fe689d1206cc198be669.webp
48KB
-
91cda0c427180f2d2466c52d017d8075.webp
9.9KB
-
0681ecc036904b8ba3e3c6c162746475.webp
7.8KB
-
503c2cf04dfb96833a1233cb8fecbee5.webp
8.4KB
-
b6fe3f754913daf62e71b002d8cee4f2.webp
19.3KB
-
b9b0f46f4b0ddbc3d086932db30667dc.webp
20.6KB
-
67e046c178970c47d5aef936b9f7726e.webp
6.5KB
-
a7b119cfc145e3cedeffea029e475590.webp
24.9KB
-
756c55c83efa84060dc55e194e1e7e48.webp
2.2KB
-
wanvideo_00003.mp4
346.9KB
-
번호제목작성자날짜조회추천
- 게시글이 없습니다.